KnowDoc
Goal
The goal of KnowDoc is to provide the best features of Stack Overflow and ChatGPT to unblock your coding journey.
Efficient unblocking through the essence of Stack Overflow and ChatGPT.
The KnowDoc project provides provides a documentation and knowledge support to software developers to make sure they can efficiently keep coding whenever they encounter a block in their work.
Main components of KnowDoc
- IDE extensions: hot keys and LSP-like protocol for neovim, VS Code to signal a block
- Backend server: authentication, user context, requests/replies,
- Knowledge base: server, schema/graph specs, ontology,
- Web client: ui for interacting with knowledge,
- Queries and knowledge context logic,
- AI-augmented information extraction and composition,
- Acquisition workflow: collects all existing knowledge and organize within KB.
Technology choices
- KB server: Neo4j,
- Neo4j client: Database.Neo4j,
- neovim extension: lua + ???,
- VS Code extension: js + ???,
- LSP communication: Language.LSP.Client,
- Git manipulations: Git,
- HTTP server: Servant,
- HTTP client: Network.HTTP.Client,
- Structured Database: Postgresql,
- DB client: Hasql,
- HTML parsing: Text.Html.TagSoup,
- Natural Language Parsing 1: NLTK,
- Natural Language Parsing 2: Stanza,
- Tokenization: spaCy,
- Sofware Engineering Ontology: SEON,
- Functional Coding Ontology: The Function Ontology,
- O-O Coding Ontology: Code Ontology,
- Web client: Elm (until Fuddle is useable),
Knowledge ingestion example
We look at establishing a knowledge base for the runConduit function of the Conduit package. Assuming the package is already flagged for ingestion, the following steps are executed:
- Data collection and parsing,
- Blocks segmentation and structuring,
- Semantic annotation using ontology,
- Block connections,
- Storage in KB,
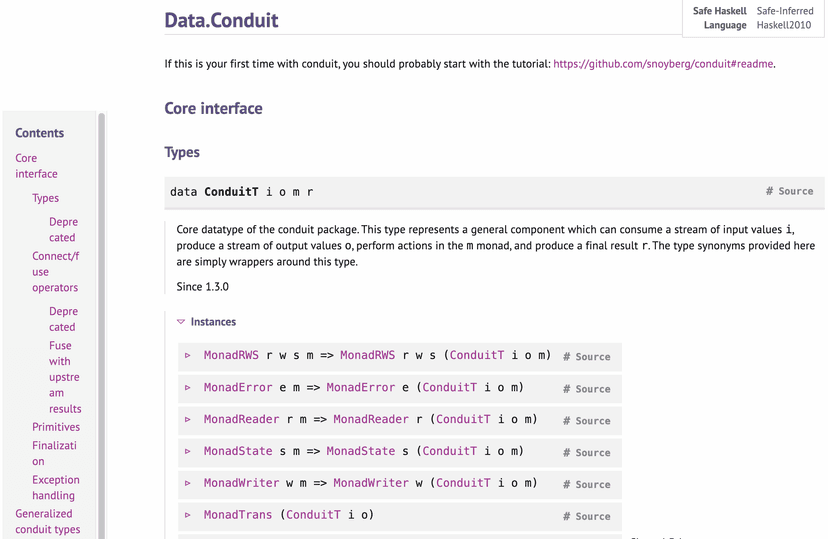
Data collection and parsing is first built from the Conduit main package description, from which the module pointer to Data.Conduit has been extracted using TagSoup on the standard structure for package description. The Data.Conduit module's webpage is also structured in a standard format from pandoc processing. The basic extraction leads to a function and explanation being created in a property graph:
(f_123456:Function {
name: "runConduit",
, description: "Run a pipeline until processing completes."
, source: "https://hackage.haskell.org/package/conduit-1.2.3/docs/Data-Conduit.html#v:runConduit"
, version: "1"
, last_updated: "2023-11-24T10:00:00Z"
, change_type: "Content clarification"
, content_type: "original"
})(e_123456:Explanation {
content: "Run a pipeline until processing completes."
, version: "1.0.0"
, created_by: "DocSyParser"
, created_at: "2023-11-24T10:05:00Z"
, content_type: "supplementary
})The following relationships are also recorded:
- (f_123456)-[:HAS_EXPLANATION]->(e_123456)
- (e_123456)-[:EXPLAINS]->(f_123456)
- (f_123456)-[:DEPENDS_ON]->(...types used in parameteres, return values and function source....)
That's the basic documentation we get for the runConduit function, which isn't that much. The next step is to augment this base to add the following blocks of knowledge:
- Function Overview,
- Signature Breakdown,
- In-depth Parameter Description,
- Return Value Explanation,
- Expanded Example Usage,
- Additional Insights,
- Related Concepts and Functions.
The processing through a quality LLM produces to these blocks:
- Overview: Executes a
Conduitpipeline from a source to a sink, yielding the final result within a monad of choice. - Signature:
runConduit :: Monad m ⇒ ConduitT () Void m r → m r- Monad m: This is a constraint indicating that in the rest of the signature, the type m is a placeholder for a real type that must implement the Monad interface. Monads are structures that represent computations.
- ConduitT () Void m r: This is an assembly of the three types
(),Voidandm runder the labelConduitT. Breaking it down, these types are used as:- (): The input type of the conduit, here (), also known as Unit, signifies that the conduit does not consume any input data.
- Void: The output type of the conduit, Void indicates that the conduit does not produce any output downstream. Void is an uninhabited type, meaning it has no possible values.
- m r: The monad m in which the conduit operates and which wraps some type r. For example, the monad type could be the
IOtype used for input/output operations, and the result type could be theStringtype to supply text back to the calling code. - Interpretation: The function takes a ConduitT that doesn't consume input from a source or generate output for a sink but performs some computation within monad m that we want to terminate in a result of type r.
- Result m r: The result is a computation in monad m that yields a value of type r.
- In-depth parameter description:
- ConduitT () Void m r:
Conduitcomputations are made to operate within a pipeline of processing. Some computations don' use or contribute to the pipeline data flow. In this case, they don't require any input data from nor produce any output data to the pipeline, but will simply perform some operation in the context of a monad and return a result of a certain type. - Why () and Void:
- (): This is the type representing the Unit concept, indicating that the conduit doesn't need any input data to begin processing. It's often used when the source of data is generated within the conduit itself.
- Void: Signifies that the conduit doesn't pass any output downstream. This is common when the conduit is a sink or when the output is consumed within the conduit.
- ConduitT () Void m r:
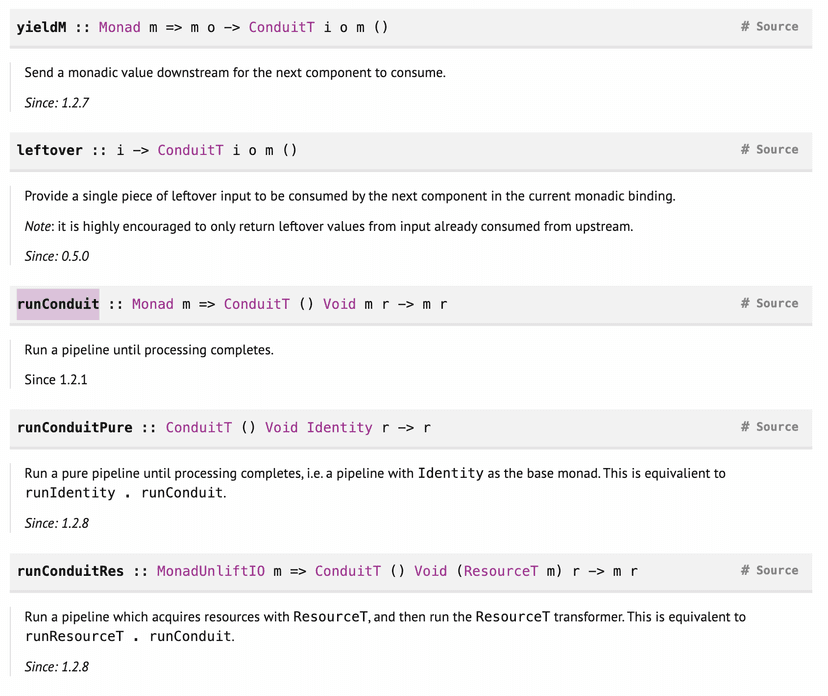
- Return Value Explanation: The return value
m rindicates therunConduitreturns a computation in some monadmthat, when executed, yields a result of some typer. The monadmcould be any monad, allowing for flexibility in how the result is computed (e.g.,IOfor input/output,Eitherfor computations that may fail with explanations). - Exemple:
- Code:
result ← runConduit $ sourceList [1..10] .| foldlC (+) 0 - Explanation:
- sourceList [1..10]: Creates a source conduit that produces the numbers from 1 to 10.
- .|: The connect operator, used to compose conduits. It connects the output of one conduit to the input of another.
- foldlC (+) 0: A sink conduit that folds the incoming stream of numbers using the (+) operator, starting from 0, effectively calculating the sum of the numbers.
- runConduit $: Executes the composed conduit pipeline.
- result ←: In a monadic context (e.g., within do notation in the IO monad), binds the result of the computation to result.
- Expected Result: The variable result will contain the sum of numbers from 1 to 10, which is 55.
- Possible Errors: Since all operations are pure and the monad m is IO in this context, there are minimal chances for errors. However, if the monad m involves IO operations, exceptions could occur (e.g., file read errors).
- Code:
- Additional insights:
- Understanding ConduitT in Context:
- Conduit as a Monad Transformer:
ConduitTcan be thought of as a monad transformer that allows for building complex data processing pipelines with effects. - Role of the Parameters Types m and r:
mdefines the computational context, andris the result produced after the conduit is run.
- Conduit as a Monad Transformer:
- Common Use Cases: Reading from files, processing streams of data, network communication, etc.
- Understanding ConduitT in Context:
- Related concepts and functions:
- runConduitPure:
- Description: A variant of runConduit that operates in the Identity monad, used for pure computations without side effects.
- Signature:
runConduitPure :: ConduitT () Void Identity r → r
- runConduitRes:
- Description: Runs a conduit within the ResourceT monad transformer, which handles resource allocation and deallocation, such as opening and closing files.
- Signature:
runConduitRes :: MonadUnliftIO m => ConduitT () Void (ResourceT m) r → m r
- runConduitPure:
Using a hybrid version of the Functional and O-O Coding ontology that matches existing structure in the Hackage documentation increases the opportunities for capturing semantic information. We use the following classes and properties to create the knowledge base:
- Classes: Function, Type, Monad, Conduit, Parameter, ReturnValue, Example, TypeParameter, Operator, Error, UseCase.
- Properties: hasParameter, hasReturnValue, hasTypeParameter, hasDescription, hasExample, relatedTo, explains, hasUseCase, canCauseError, producesResult, synonymTo.
Visual Presentation
The current Haddoc / Hackage documentation style can be much improved, especially when aiming for a much more interactive and assisted use of information.




For example, we can use an animated knowledge browser as in the following design that calls on graph browsers and the Smalltalk click-to-dig-in approach:
I made the transitions feel like the new topic is "pushing" the old one out and added inline links and...
— Amelia Wattenberger 🪷 (@Wattenberger) November 22, 2024
I'm finding this strangely addictive!
what's really fun is how different the paths can be - I refresh partway through and end up in a completely different area pic.twitter.com/CyGPgpXOfx
Another approach is to use blocks in rows and columns:
Documentation System
Main Topics
Getting Started
Introduction to the documentation system.
Installation
Steps to install the software.
Configuration
How to configure the system settings.
Modules
Authentication Module
Handles user authentication and authorization.
Database Module
Manages database connections and queries.
API Module
Facilitates communication with external APIs.
Functions
Login Function
Allows users to log into the system.
Register Function
Enables new users to create an account.
Fetch Data Function
Retrieves data from the server. For more details, refer to the API Documentation8.
Types
User Type
Defines the structure of a user object.
Product Type
Defines the structure of a product object.
Order Type
Defines the structure of an order object.
Another approach yet is a more complex layout with subsections, vertical nav paths and expecting a wide aspect ratio output:

from Stefania Passera site.
Edward Tufte is always a fantastic source of inspiration, but his work is much more geared toward numerial and engineering information than mostly text blocks. We can look at the ideas embedded in the Tufte-css package but can't use much of that.
Legal documents feel more like the place to look for ideas. For example, Legal Tech Design presents many kind of layouts for dense and complex documents, such as 
Additional ideas lie in the TeX section of StackExchange. For example,Showcase of Game documentation presents many pages of structured and dense information: